
Plotting the most referenced Refactorings with Node.js, PDF.js, and Chart.js
Refactoring (2nd Edition) by Martin Fowler is one the best programming books I have read. Full stop. I have utilized this book to train and coach developers on my team, improve the design of my code, and grow as a professional. Similar to Pragmatic Programmer, Clean Code, and others, this book helped me level up as an engineer.
After reading the book, I wanted to ascertain which refactorings Martin (yep, we on a first name basis) referenced the most.
Why?
Because I was curious. Almost every refactoring listed in the book depends upon another refactoring. For example “Extract Function” mentions “Split Variable (240)” and “Replace Temp with Query (178)”. While I may utilize “Extract Function” often, could I improve the design of my code by better understanding those other two refactorings?
After reading the book, I had my list of fundamental refactorings, key techniques that I used in my own code and coached peers, senior engineers, and junior developers on. However, what if I was missing something? What if there was a refactoring that I glossed over, but was referenced numerous times as a “prerequisite” for others that I should take a second look at. For example, after crunching the numbers I want to revisit “Replace Conditional with Polymorphism”.
Furthermore, maybe I could gleam a bit of what Martin finds important or uses the most. Could this information help me recommended to peers and other engineers certain refactorings to check out or “start with first”. Martin tells the reader to read the first 100 pages, then skim the refactorings. OK, but is there anything I should skim a little bit more?
Lastly, I wanted to experiment with Chart.js and PDF.js. to plot the data. A new opportunity, a new thing to learn, you know us engineers, we like that new and shiny. So, let’s shine!
Graph time!
Sections
- The Results aka Them Charts!
- Algorithm and Process (How the deed was done)
- Conclusion
- Additional Resources
The Results aka Them Charts!
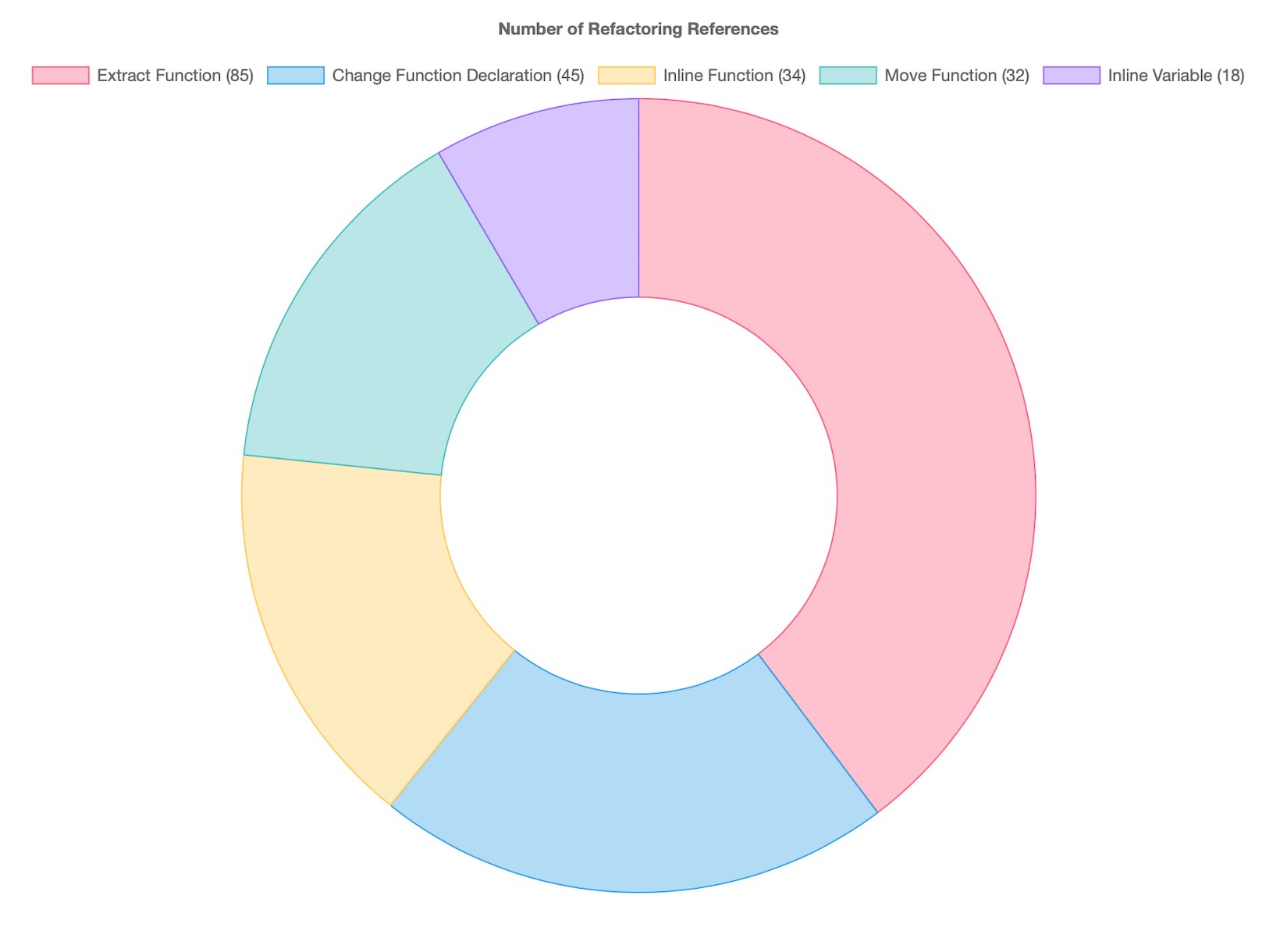
The top 5 referenced refactorings
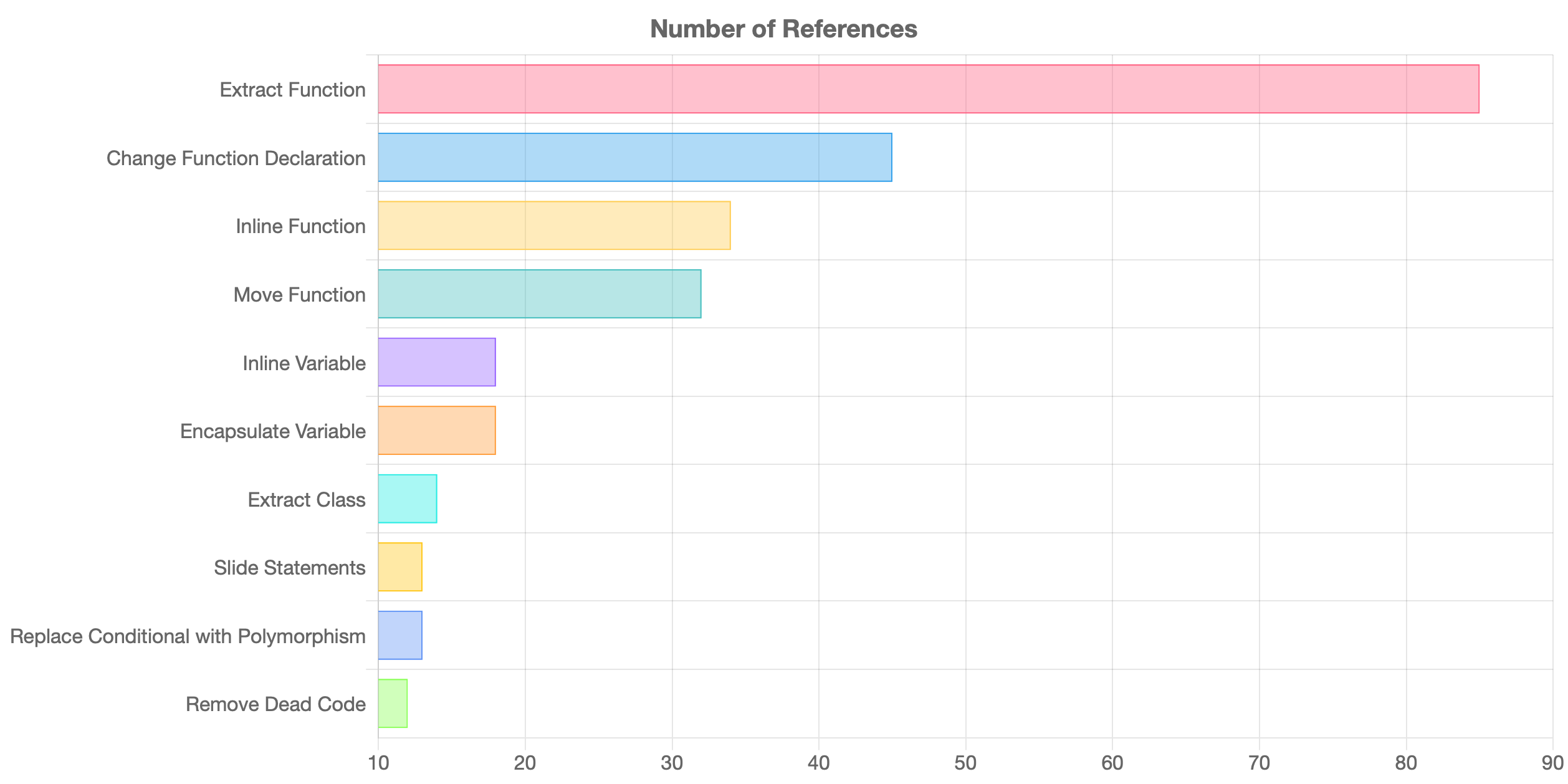
The top 10
The top 25
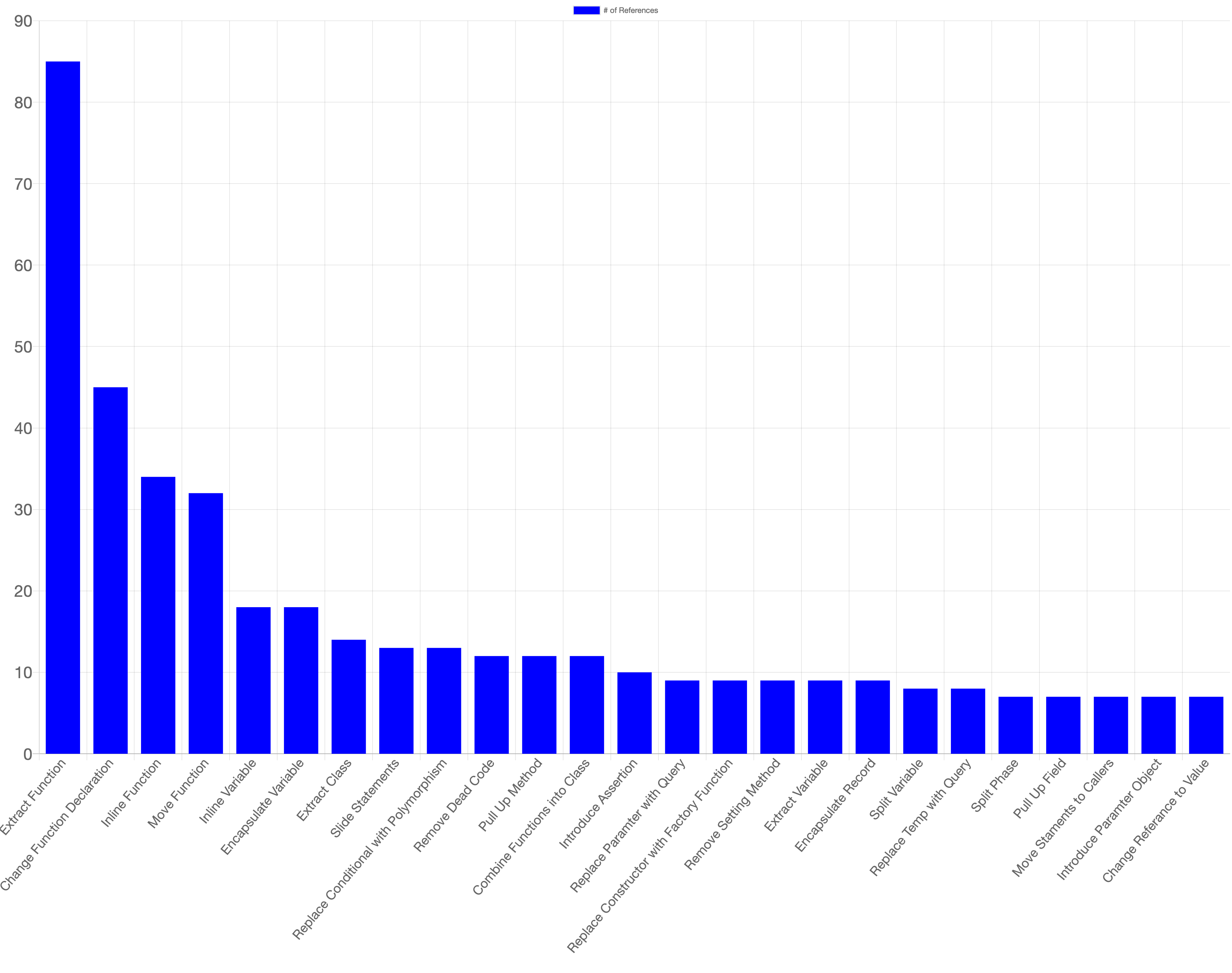
Please note that there are over 60 refactorings and plotting all of those barely fits (legibly) on the screen. To see the full data set, click here.
So what does this data tell us?
Well I knew the king of the land was (and is) “Extract Function”. If there is one refactoring you learn, let it be this one! It is referenced almost twice as much (85) as the next refactoring “Change Function Declaration” (45). It is the building block for numerous refactorings.
Additionally, techniques related to refactoring functions are highly referenced. As we know, functions are an essential building block of our programs, so it makes intuitive sense that these refactorings would rate highly. While this was insightful, I did not think four out of the top five would be related to functions!
Not only are the first four refactorings related to functions, but there is also a bit of a drop after these four. The top four are each mentioned almost twice as much as the 5th most referenced refactoring (“Inline Variable”), which is the first non-function related refactoring.
My original hypothesis was that the following refactorings would be referenced the most:
Extract Function
Move Function
Extract Variable
Inline Function
Rename Variable
Combine Function into Class
So yeah…I was off!
In short, I hypothesized that there would be more references to refactorings related to variables and classes. And this is why we do the experiment!
Now, because a refactoring is mentioned more than another does that make it more important? No. While “Extract Function” is essential, there are additional refactorings such as “Rename Variable”, “Replace Temp with Query”, and “Decompose Conditional” that are fundamental to making cleaner, maintainable, self-documenting, and more economic code.
Now that we’ve discussed the data, how did we do it?
Part 2: How the deed was done.
In this section I outline my algorithm, process, and pieces of the code that brought this to fruition. My intent is to provide insight into some of the more nuanced elements of developing this project that will hopefully help you when/if you try out these tools or embark upon your own endeavor. All the code for this project can be viewed here.
My initial thoughts and high level ideas
There are over 60 refactorings mentioned within the book and over 450 pages! Where to begin?
My idea was to convert the book (i.e. pdf) to text (e.g a string) and perform a series regular expressions on the string to obtain the number of times a particular snippet (i.e. match) was found. Once I had the number of times a refactoring was mentioned, I would then plot this data!
A quick note: I did not just search for the string of a refactoring, but the actual page number that it appears on. This was to avoid references to the refactoring that occurs in its own chapter. For example, if I were to search for “Extract Function” then I would get all of the references including those in its own section, potentially skewing the data! I do not want to include those. What I noticed is that Martin references the refactoring plus it’s page number (e.g. “(106)”) when one refactoring refers to another. Based on this, all of my searches are based on the page number of the refactoring.
Algorithm, process, and code breakdown
- Prerequisite: Create a data structure with the list of refactorings and page numbers
- Use PDF.js to read the pdf book into memory
- Save the text in the pdf to a file
- Read the text file into memory with Node.js
- Use regular expressions to find the references (based on the list of refactorings and page numbers)
- Save the references as a data file
- Use Chart.js to plot the data
- Save charts as images
- Get some sleep!
Create a data structure based on the first page of Refactoring
In the hardcover version of the book, all refactorings are listed with their corresponding page number. I saved this information as a json file and used it for the regular expressions to find the number of references.
refactoring-page-numbers.json
{
"Change Function Declaration": "124",
"Change Reference to Value": "252",
"Change Value to Reference": "256",
"Collapse Hierarchy": "380",
"Combine Functions into Class": "144",
"Combine Functions into Transform": "149",
"Consolidate Conditional Expression": "263",
"Decompose Conditional": "260",
"Encapsulate Collection": "170",
"Encapsulate Record": "162",
"Encapsulate Variable": "132",
"Extract Class": "182",
"Extract Function": "106",
"Extract Superclass": "375",
"Extract Variable": "119",
"Hide Delegate": "189",
"Inline Class": "186",
"Inline Function": "115",
"Inline Variable": "123",
"Introduce Assertion": "302",
"Introduce Parameter Object": "140",
"Introduce Special Case": "289",
"Move Field": "207",
"Move Function": "198",
"Move Statements into Function": "213",
"Move Statements to Callers": "217",
"Parameterize Function": "310",
"Preserve Whole Object": "319",
"Pull Up Constructor Body": "355",
"Pull Up Field": "353",
"Pull Up Method": "350",
"Push Down Field": "361",
"Push Down Method": "359",
"Remove Dead Code": "237",
"Remove Flag Argument": "314",
"Remove Middle Man": "192",
"Remove Setting Method": "331",
"Remove Subclass": "369",
"Rename Field": "244",
"Rename Variable": "137",
"Replace Command with Function": "344",
"Replace Conditional with Polymorphism": "272",
"Replace Constructor with Factory Function": "334",
"Replace Derived Variable with Query": "248",
"Replace Function with Command": "337",
"Replace Inline Code with Function": "222",
"Replace Loop with Pipeline": "231",
"Replace Nested Conditional with Guard Clauses": "266",
"Replace Parameter with Query": "334",
"Replace Primitive with Object": "174",
"Replace Query with Parameter": "327",
"Replace Subclass with Delegate": "381",
"Replace Superclass with Delegate": "399",
"Replace Temp with Query": "178",
"Replace Type Code with Subclasses": "362",
"Separate Query from Modifier": "306",
"Slide Statements": "223",
"Split Loop": "227",
"Split Phase": "154",
"Split Variable": "240",
"Substitute Algorithm": "195"
}
Use PDF.js to read the file into memory
You can find the full source here. My code is heavily inspired by the PDF.js example of getinfo.js.
One important change I made was to handle newlines and spaces:
return page.getTextContent({normalizeWhitespace:true}).then(function (content) {
// Content contains lots of information about the text layout and
// styles, but we need only strings at the moment
const strings = content.items.map(function(item, index, array) {
//.transform[5] is the y position of the current line
//if a new "y", then its a new line, so add newline character
let str = item.str;
if (index > 0 && item.transform[5] !== array[index-1].transform[5]) {
str = '\n' + str;
}
return str;
});
//...more code, promises, etc.
});
Important to note in the snippet, is that we want to ensure we are adding a new line character at the appropriate place. If we do not do this, lines will jumble together and make it harder for us to utilize our regular expressions later. We also normalize the white space, which according to the source
replaces all occurrences of whitespace with standard spaces (0x20).
This helped both in programming and automated/manual testing (e.g. ctrl+f in an IDE) to double check our logic.
Save the text in the pdf to a file
//textContent is the pdf as text
//outputFile, e.g. 'refactoring.txt`
fs.writeFile(outputFile, textContent, (err) => {
if (err) throw err;
});
Read the text file into memory with Node.js
const file = '../pdf/assets/refactoring.txt';
//additional code removed for brevity
fs.readFile(file, 'utf8', (err, data) => {
if (err) throw err;
const refactorings = createListOfRefactorings(data);
sort(refactorings);
createDataForChart(refactorings);
writeRawData(refactorings);
});
This is the most straightforward piece and shows how I like to make my entry point “TL;DR”. The file is the refactoring.txt which we saved down with our pdf module.
Use regular expression to find the references
Now that we have read the file, we can now search it for instances of each refactoring. The data is the in memory text file of the refactoring book as a string.
function createListOfRefactorings(data) {
const pageNumbers = getRefactoringPageNumbers();
const refactorings = [];
for (let key in pageNumbers) {
let re = new RegExp('\\(' + pageNumbers[key] + '\\)', 'ig');
refactorings.push({
name: key,
page: pageNumbers[key],
references: data.match(re).length
});
}
return refactorings;
}
let re = new RegExp('\\(' + pageNumbers[key] + '\\)', 'ig');
This above line is the meat, which searches the entire file (e.g. ‘g’) and is case insensitive (e.g. “i”), where pageNumbers[key] would be 106, in the case of “Extract Function”. As we loop through we push each object onto our array of refactorings and return the result.
Save the references as a data file
createListOfRefactorings makes an array of objects for each refactoring with its name, page number, and the number of times it was referenced. You can find the full data set here, below is a snippet of the results:
[
{
"name": "Extract Function",
"page": "106",
"references": 85
},
{
"name": "Change Function Declaration",
"page": "124",
"references": 45
},
{
"name": "Inline Function",
"page": "115",
"references": 34
},
{
"name": "Move Function",
"page": "198",
"references": 32
},
{
"name": "Inline Variable",
"page": "123",
"references": 18
},
//...more records
{
"name": "Replace Nested Conditional with Guard Clauses",
"page": "266",
"references": 1
}
]
However, this is not the way chart.js needs the data structured.
Use Chart.js to plot the data
Ok, so Chart.js needs an array of labels (e.g. the names of all refactorings) and the data to plot (e.g. the number of references). I simply converted one data structure to the other and ended up with the following
{
"labels": [
"Extract Function",
"Change Function Declaration",
"Inline Function",
"Move Function",
"Inline Variable",
//...edited for brevity...
],
"data": [
85,
45,
34,
32,
18,
//...edited for brevity...
]
}
This we could now plug into chart.js and voila…CHARTS!!!!
Save charts as images
I was inspired by an article that was like “hey have charts in your post” and I wanted that, so I made it. Chart.js is very easy to make charts with. However, ya boy needed pretty pictures for the blog.
Hmmmm? A dilemma.
Chart.js has a function that returns the base64 encoded string. Once I have that I could create an image like so:
chart.toBase64Image();
And then built a function to dynamically make an image
const createImage = (chart, width=350, height=350) => {
const data = chart.toBase64Image();
const image = new Image(width, height);
image.src = data;
document.body.appendChild(image);
}
Once I had this image, right click, save as, and boom, charts! Whoa, no code for that you say? Nah, not at this time, this pet project already turned into a tiger, soon to be a titan, so I will enhance as times goes on. Version 1 my friends!
Conclusion
Refactoring is an essential read. If you are an experienced engineer, many of the techniques in the book you may have already used. However, this book gave me the vocabulary, the words needed to describe what I was doing as well as the how. In turn, I could more easily coach members of my team on these techniques.
Given my passion for this book and how I saw the lessons it outlined positively impact my team, I wanted to dive it and determine which refactorings were most often referenced. So yeah, we did that! We obtained and plotted the data all while trying out new libraries, making pretty graphs, and experimenting with modern techniques. Definitely check out the code, explore refactoring, and continue to push!
Happy coding, happy learning, and keep leveling up!